【译】Exploring How Cache Memory Really Works
本文最后更新于 2024年8月6日 凌晨
尽管我们经常听到 L1、L2、高速缓存块等术语,但大多数程序员对高速缓存的真正含义和作用所知甚少。在本文中,我们将简要解释什么是高速缓存、如何实现高速缓存以及高速缓存的必要性。

在我的编程知识库中,有一样东西必不可少,那就是 CPU 缓存。缓存是一把双刃剑,它能让懂得如何处理缓存的程序员的生活变得更轻松,而让不懂得如何处理缓存的程序员的生活变得异常艰难。在讨论高速缓存之前,我们首先需要了解 RAM(随机存取存储器)。RAM 是一种著名的临时内存,关闭计算机后,内存内容就会丢失。我们通常认为它是一个由 0 和 1 组成的长数组,但实际上 RAM 的工作原理与此截然不同!使用表格类比是更好的思考方式。

这种 “表格”式内存布局使高速缓存更容易访问内存。高速缓冲存储器内部可以加载 N 个内存块。缓存块的大小各不相同,缓存块的数量通常是 2 的幂次。从现在起,我们将这些内存块称为 高速缓存行(Cache Line) 。当缓存行被存储到缓存中时,我们也会存储其内存位置。
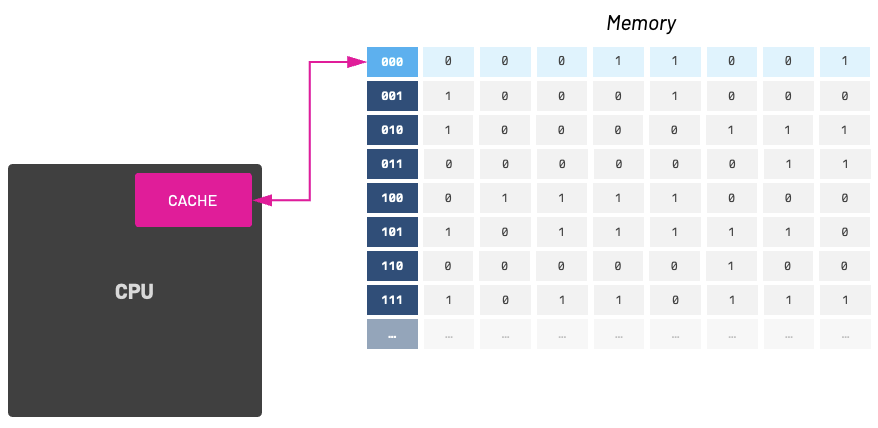
当我们成功存储和获取一个缓存行时,我们称之为缓存命中(cache hit),否则就是缓存缺失(cache miss)。作为具有缓存意识的程序员,我们应该努力提高缓存命中率,避免缓存缺失。请注意,不同的处理器微体系结构会指定不同大小的缓存行。例如,我使用的笔记本电脑是基于苹果 Silicon M2 Pro 芯片的 MacBook Pro。我可以使用 macOS 上的 sysctl 终端命令查看该架构的缓存线大小:

当我在运行英特尔酷睿 i9 处理器的老款 MacBook Pro 上运行相同命令时,得到的缓存行大小值不同:

我的老款英特尔笔记本电脑的缓存行大小为 64 字节,而新款 M2 Pro 笔记本电脑的缓存行大小为 128 字节。缓存行大小(或缓存块大小)是传输到主内存和从主内存传输过来的数据单位。它对 CPU 如何有效地与内存子系统进行交互有重大影响。有了更大的高速缓存行,您就可以更有效地利用数据的空间位置性(邻近性)。

缓存:它有什么作用?
在早期的计算机中,CPU 和 RAM 之间的速度差异很小。例如,早期的个人电脑(包括 80386 在内)根本没有高速缓存。所有内存操作都是从 CPU 到主内存,然后再返回。随着中央处理器的速度与内存速度相比不断提高,人们需要以某种方式缩小这种差距。答案就是高速缓冲存储器。
这种新方法是在处理器上设置一个临时数据存储器,用于保存可被高速访问的、经常需要的小比特数据,从而提高 CPU 的处理效率。
缓存比内存(RAM)更快
由于我们的高速缓存位于 CPU 内部,因此处理器的其他部分对它的读写速度要快得多。
大多数现代 CPU 高速缓冲存储器由不同级别的存储组成。这些级别通常称为 L1、L2、L3,有时也称为 L4。它们的位置、速度和大小各不相同;大多数机器至少有两级缓存: 大多数机器至少有两级缓存:L1 和 L2。
L1 容量小,但速度极快。L2 速度较慢,但存储空间较大。L3 是三者中速度最慢的,但通常也是存储容量最大的。

L1 缓存有多快?
当我说 L1 更快时,我的意思是真的更快!从这个角度来看,访问 L1 缓存需要约 3 个 CPU 周期,访问 L2 缓存需要约 10 个 CPU 周期,而访问普通 RAM 则需要约 250 个 CPU 周期。
缓存在哪里?
从 1989 年推出英特尔 486DX 开始,英特尔在 CPU 本身增加了一个很小的高速缓存。486 芯片中嵌入的小型高速缓存大小为 8 KB,在后来的产品中被称为 “一级 “高速缓存。随着制造商开始采用 486 CPU,他们也开始在主板上加入二级缓存。这种外部高速缓存被称为 “二级 “高速缓存,通常使用 SRAM 芯片,其访问时间约为 15 或 20 纳秒(而普通主内存的访问时间为 70 纳秒)。下图是 486SX 的主板,带有两级缓存: 一级缓存位于 CPU 芯片内部,二级缓存位于主板外部。

最初的奔腾)芯片使用的是分离式一级缓存,每级缓存大小为 8 KB;8 KB 用于数据缓存,8 KB 用于指令缓存。1995 年,奔腾 Pro 芯片引入了 P6 x86) 微体系结构,并以板载高速缓存而闻名。缓存大小为 256 KB、512 KB 或 1 MB。

更多的现代架构在缓存布局方面更加智能,并考虑了多个 CPU 内核。

下面是一个包含 L1、L2 和共享 L3 高速缓存的多核 CPU 架构示例。Nehalem)微体系结构用于第一代英特尔酷睿 i5 和 i7 处理器。

数据缓存 & 指令缓存
必须提到的另一个点是,大多数计算机都有一个专门的指令缓存(i-cache)和另一个数据缓存(d-cache)。正如我们所期望的那样,指令缓存存储程序指令,而数据缓存存储数据。指令缓存存储汇编/操作码指令,数据缓存存储从主存储器访问的数据。
这种分离的原因与我们正在访问的内容的性质以及我们期望访问数据的方式有关。例如,在假设计算机将连续运行多条指令的情况下,可以分块获取程序指令。因此,由于我们假定取指令是连续的,因此取指令的效率会更高。
另一方面,我们不能假定来自主内存的数据是连续的,数据缓存的实现将尽量只获取被请求的数据。另外补充一下,如果你了解到PS1(是的就是Playstation的第一代)是一个只拥有4KB 的指令缓存的机器,它并没有一个合适的数据缓存。编写能有效利用指令缓存的 PS1 代码是一项挑战,但为了让游戏运行流畅,开发者经常需要这样做。
Scratchpad:大多数 MIPS 处理器都有一个数据缓存,但 PlayStation 并没有采用适当的数据缓存。相反,索尼分配了 1 KB 的快速 SRAM,大多数开发人员将其称为 “Scratchpad“。在 PS1 上,Scratchpad 被映射到内存中的一个固定地址,其目的是为程序员提供一个更灵活的 “缓存系统”。
即使 Apple Silicon M1 和 M2 芯片也有独立的指令和数据缓存。M2 高性能内核有 192 KB 的 L1 指令缓存、128 KB 的 L1 数据缓存,并共享 16 MB 的 L2 缓存,而节能内核有 128 KB 的 L1 指令缓存、64 KB 的 L1 数据缓存,并共享 4 MB 的 L2 缓存。

在我的笔记本电脑(运行在苹果 Silicon M2 Pro 上)上再次调用 sysctl 命令,我们可以看到 L1 和 L2 缓存大小的值:

在我使用英特尔酷睿 i9 处理器的老款 MacBook Pro 上执行相同命令时,我得到的 L1、L2 和 L3 缓存大小值各不相同:

你看到 L1 的 icachesize 和 dcachesize 中指令高速缓存和数据高速缓存的大小是有哪些不同的吗?
数据放在缓存的哪个地方?
有许多缓存放置策略。一些流行的放置策略包括直接映射高速缓存、完全关联高速缓存、集合关联高速缓存、双向倾斜关联高速缓存和伪关联高速缓存。直接映射高速缓存是最简单的方法,每个内存地址正好映射到一个高速缓存块。高速缓存分为多个组,每个组只有一条高速缓存线。由于本文旨在为初学者提供友好的教学,因此让我们简化一下,只介绍直接映射高速缓存。下面是一个非常简单的例子:16 字节内存和 4 字节高速缓存(4 个 1 字节块)。

存储标号为 0, 4, 8, 和12 的数据均映射至缓存块 0.
存储标号为 1, 5, 9, 和13 的数据均映射至缓存块 1.
- 存储标号为 2, 6, 10, 和14 的数据均映射至缓存块 2.
- 存储标号为 3, 7, 11, 和15 的数据均映射至缓存块 3.
该如何计算映射?
使用余数运算符是找出特定内存地址应进入哪个高速缓存块的一种方法。如果高速缓存中包含
$2^k$块,那么内存地址 $i$ 处的数据将进入高速缓存块索引:
例如,使用 4 块高速缓存时,内存地址 14 将映射到高速缓存块 2:
这种取模操作在计算机上很容易实现,因为它相当于屏蔽内存位置的最小有效位。鉴于我们的高速缓存长度为 4 字节,我们可以查看地址的最后有效的$k$位。

如何缓存中的数据?
我希望大家清楚,我们的缓存块索引 1 可能包含来自地址 1、5、9 或 13 的数据。当然,这一逻辑对所有其他缓存块也是成立的,所以问题实际上变成了 “我们如何区分这些映射到相同缓存块索引的潜在地址?“解决这一问题的方法之一是在高速缓存中添加标记。这些标记提供了其余的地址位,让我们可以区分映射到同一高速缓存块的不同内存位置。

有效位:我们在缓存中存储的最后一个信息即为有效位。开始时,高速缓存是空的,所有有效位都被设置为 0。当数据加载到特定的缓存块时,相应的有效位标志会被置 1。
同时希望大家已经清楚,高速缓存并不仅仅包含内存中数据的原始副本;它还包含元数据和额外的位,以帮助我们在高速缓存中找到数据并验证其有效性。
带着缓存思想进行coding
作为码农,编写对缓存友好的代码非常重要。正确使用电脑或游戏机的缓存确实会影响软件的性能,尤其是在采用多核和大缓存设计的现代机器上。让我们来看几个极其简单的例子,试着了解一下缓存访问方面的情况。
例子1:缓存局部性
大多数的数据应当保存在连续的存储位置。 这样,当代码发送第一个访问请求时,大多数的数据将被用将得到缓存。 这和我们选择的数据结构密切相关。我们尝试保持:
- 良好的时间局部性:旨在可以重复访问,刚刚被访问过的元素,极有可能在不久之后再次被访问到
- 良好的空间局部性:旨在可以单步访问,将被访问的下一个元素,极有可能就处于之前被访问过的某个元素的附近;
下面我们用C编写代码来举个例子,期间有两个函数会循环计算矩阵中所有元素的总和。对缓存友好的代码应尊重矩阵的 stride-1 模式。
1 | |
第二个函数会翻转访问方式,先循环矩阵的所有列,然后在内部嵌套行循环:
1 | |
想要从数据存储的角度理解为什么第一个函数比第二个好,我们就需要明白C的数组是按行主序的方式进行排列的。换句话说,数组的每一行的数据在存储上是连续的。

如果缓存大小足够小,那么第一个函数的缓存命中率会高很多。
链表:关于数据局部性的争论也是链接表如今名声不佳的原因。从面向数据的设计角度来看,链接项可能遍布内存,这就会导致缓存缺失。

例子2:避免复杂的循环
让我们看一段简单的代码,动态分配三个数组并初始化其元素:
1 | |
非常简单!每个数组有 16 个元素,每个元素是一个 16 位的整数。为了简单起见,我们假设缓存可以容纳 256 个字节。

现在我们编写一个简单的循环然后把数组内所有的元素加起来:
1 | |
由于我们的缓存大小只有 256 字节,一次只能处理 16 个 16 位整数。这对我们来说是个坏消息!当我们循环访问三个数组的条目时,循环开始时缓存的元素将在迭代结束时从缓存中删除。在这种情况下,考虑到缓存的大小为 256 字节,我们将出现缓存缺失。

一种做法是,服务员先询问第一桌点了什么菜,然后询问第二桌点了什么菜,接着询问第三桌点了什么菜。服务员接着问第一桌点第二份菜,第二桌点第二份菜,第三桌点第二份菜。如此重复,直到写下所有的点单。
如果服务员在完成第一桌的全部点菜后,再去询问第二桌和第三桌的点菜,不是更好吗?因此,解决这种特殊情况的更好办法是编写单独的 for 循环。呵呵!是的,这听起来好像代码的性能会变差(如果我们不必要地这样做,性能会变差)。但在这种情况下,为了避免大量的缓存缺失,我们最好将循环拆分成更小的循环。
1 | |
例子3:结构对齐
C 语言中的结构体是一种非常有用的将变量打包成一大块内存的方法,但它们有自己特殊的内存分配方式。如果你是 C 语言的新手,你会惊讶地发现我们在声明结构体时可能会 “浪费 “内存。
在 C 和 C++ 中,每种数据类型都有一个大小,可能是 8 位、16 位等。因此,如果结构体是这些数据类型的集合体,你可能会推断出结构体的大小将是其所有类型的总和,但如果您的结构体内部有不同的类型,这种推断就大错特错了。
这是因为结构体有一个天然的对齐方式,即最大成员的大小。因此,如果一个结构体有两个成员:一个 32 位,一个 8 位,那么对齐方式就是最大值的大小: 32 位。在这种情况下,该结构消耗的总内存为 64 位!
1 | |

再来看一个例子,我们的结构有两个以上的成员:
1 | |
由于最大的成员是 32 位,因此我们知道结构体的对齐方式是 32 位。请观察对齐方式如何直接影响内存中结构体的大小:

请注意,结构对齐方式要求在第一个和第二个成员之间添加填充,并在末尾添加另一个填充(以填充对齐方式)。我们可以通过重新排列结构成员的顺序来改善情况。看看如果我们改变第二和第三个成员的顺序会发生什么:
1 | |

通过调整对齐方式和成员顺序,我们减小了结构体的大小。这样做的意义在于,减少内存占用空间可以帮助我们更好地将数据放入缓存行,从而减少缓存缺失。
有些码农也会通过简单地分割数据来解决这个问题。为了避免数据变大时出现内存泄露和缓存缺失,我们可以将这些数据存储为单独的值,而不是将它们捆绑在一个结构体中。因此,如果我们想拥有一个结构体的多个实例,只需将它们视为两个大小相同的独立数组即可。
1 | |
这样,我们对这些值使用每对40 位,而不是 64 位。
例子4:编译器标志
现在的编译器比较智能了,因此我们可以通过为项目设置正确的编译器标志来帮助编译器。编译器优化的一些例子包括展开循环、优化函数调用、矢量化和填充数据结构。
总结一下吧!
有了这些关于计算机内存如何工作以及它如何与 CPU 一起工作的新知识,希望你能在高速缓存操作方面走得更远。正如我所提到的,这些都是非常简单的例子,但它们所展示的思想却是缓存工作原理的基础。
之后我该怎么学习?
您可以从最基本的开始,比如编写简单的程序并尝试对其进行基准测试;组织结构并尽可能做到最好!您还可以重构代码,使其更快。从这里开始,一切都是进化!如果你喜欢这篇博文,可以在 X/Twitter @lemmtopia 上关注原作者~